
Door Anne Bruinsma
Results Carbon Farming Pilot
For the past two years we have been a technical partner in a Carbon Farming pilot within the Ploutos project. The project aims to create more environmentally, socially and economically sustainable opportunities in the agro food sector. Our pilot focussed on developing a Carbon Tool to reliably quantify soil organic carbon according to international carbon credit schemes. ZLTO headed the project, with Udea (a leading organic trader that wishes to compensate for their carbon emissions during transport) and Farmhack as project partners. In our final post on the project, we describe some of the technical results of our project.

Introduction
Carbon farming has been an important innovation theme for the ZLTO for the past few years. Economically it could become an interesting focus for farmers, by creating a direct additional source of income through carbon credits. Increasing soil carbon contents also has positive effects on biodiversity, climate change and overall health and resilience of soils. This leads to social rewards, and also – more indirectly – to financial gains as healthy soils lead to less fluctuation in yields and therefore in income.
Strategically ZLTO has opted to embed the Carbon Tool as additional functionality the pre-existing ‘Monitor Ecosystem Services tool’ (BBWP). This decision was made on technical and strategic grounds, to show mutual benefits towards other farm environmental key performance indicators (such as nitrogen, water quality/quantity and phosphorus). Through the BBWP, ZLTO offers farmers a complete quantitative overview on their ecosystem services.
ZLTO wants to support farmers by providing robust and trustworthy carbon farming planning for the long-term. We also needed to look at ways to reduce administrative burden , and to increase awareness among farmers on the value of data collection and data ownership. In this blogpost we focus on sharing our results on the relevance and applicability of machine data in this regard.
Relevance Machine Data
An important challenge is the availability and collection of data on farm level, linked to carbon sequestration, eg. data regarding the implementation of different soil management techniques and data based on soil samples. Not all relevant activity is being registered, and not all of the relevant data regarding soil management and soil condition is freely available in a machine readable manner.
Cultivation activities that were considered relevant as input for the carbon model used in our pilot:
- Tillage activity: Tillage activity increases soil carbon loss to the atmosphere (ref). Reduced tillage or “no-till” measures are therefore seen as relevant.
- Seeding activity/date: The seeding date provides the start date of the crop. Together with the harvest or end date of the crop, this indicates the amount of time the crop was covering the field.
- Harvest activity: Harvest activities such as leaving straw, contributing to carbon levels when it’s ploughed under in a later stage.
- Surface area: The amount of surface area of a particular activity acts as a weighing factor for the impact of a specific activity.
- Addition or removal of organic matter: Adding compost or other organic matter to the field to increase soil carbon levels.
We explored how machine data could be a reliable automated source for these types of activities. We explored whether the collected information can be used as a) proof that a farmer actually implemented carbon sequestration measures and b) automatic input to the carbon model for more accurately forecasting the carbon sequestration based on more detailed data.
Dealing with machine data
We equipped a farm tractor with logging equipment to track its activities throughout the year. Each second the tractor engine was on, a datapoint was created with its location and other measurement values, resulting in a GPS track with metadata. We used this logging data to supply automated inputs for the compensation model for carbon sequestration. The idea ultimately is that the combination of a tractor and an implement create high quality data in an automated fashion that can reduce the manual labor involved.
In order to supply automated inputs we transformed the collected data to generate a list of activities from the raw data. We developed an experimental software setup for this during the Carbon Hack. The example in the figure below shows a field where cauliflower was harvested bit by bit. The second row (blue) shows NDVI values of the same plot (determined by satellite data).
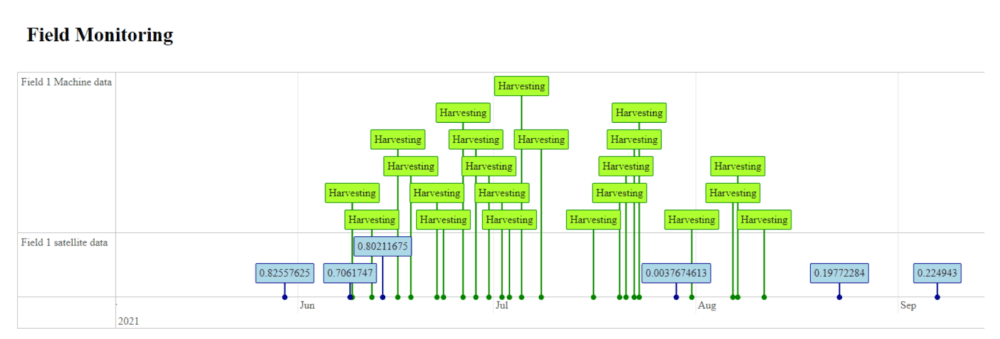
The main categories of interest from the raw data for carbon sequestration are:
- Soil moving operations (categories primary and secondary soil operations)
- Planting / seeding (planting category)
- Fertilizing (all fertilizing categories)
- Harvesting (all harvesting categories)
Filtering the raw data leads to a list of events that indicate what carbon related activities have taken place at a certain parcel. For each of these activities, the total amount of surface area that was worked was calculated using the GPS coördinates included in the raw data points. The end result was a type of operation with a date and worked area. We made this result requestable by the Ploutos Interoperability Enabler (PIE) through an API. Once the data was analyzed it could be made available as an input to the Carbon Tool. Custom endpoints were developed to provide a list of events based on a given polygon, and expose the categorization system.
Applicability machine data for monitoring purposes
As carbon sequestration is a relatively slow process (measurable over spans of 10 years) it is important to ensure consistent application of the carbon measures. Compared to soil sampling, machine data can provide a more continuous and valuable additional monitoring tool.
Machine data is accurate, and when the farm is set up properly, fairly complete. However, machine data is most beneficial for identifying implementation of measures – as opposed to measures that require refraining from certain activities. The reliability of the data to prove the absence of reduced tillage or no-till measures for instance, is reduced.
To increase reliability in detecting the absence of critical events, it is recommended to combine machine data with high quality satellite data. Even though satellite data is not always complete, it can help fill in blank spots when machine data is not available. This can both confirm or disprove suspicions of undesirable activity.
Our research shows that machine data provides supporting evidence that the farmer acts as planned. Machine and implement offer rich series of events. Our data analysis indicated that machine data can provide evidence that indicates a high degree of compliance with what was originally planned (in the Carbon Tool). A compliance of over 80% as targeted in the execution plan is achievable.
Applicability for forecasting carbon sequestration
The potential of machine data to improve the accuracy of forecasted carbon sequestration is clear. Structured machine and implement data can serve as input data for such calculations. However, there are still many challenges that need to addressed.
- Machine data might not always be sufficient to get to decisive information. Some values are simply not known by the tractor or implement, as not everything is being sensed. There are still critical data points that can only be collected by sampling or weighing.
- Not all available data is easy to integrate into the carbon calculation model. A good example of this is data of tillage activity and the related carbon loss from the soil. The exact type of equipment and worked area and depth might be known, but using this in a carbon model is not straightforward. While it is known that reduced tillage can help with maintaining more carbon in the soil, it is hard to quantify what the exact impact is on the carbon level in the soil. The exact carbon loss might vary per type of soil, but also the current condition of the soil, and the type of equipment used. Not all this reference data is available.
It’s important to note that the availability of machine data as a log serves as a basis to collect critical missing data such as quantities, kg’s/hectares etc. Collecting all data manually would create a significant administrative burden, but adding these points to a detailed activity log is much easier. (ps: manipulating input data will make the forecast inaccurate, so there is little incentive to do so).
Conclusions
Machine data is a good additional component for monitoring the implementation of carbon measures in arable farming. The realized reliability and accuracy of inputs are higher than using fixed reference numbers, as the actual dates and activities are tracked. Considering there is a cost to collecting machine data, how the added reliability is valued in the carbon credit certification program is a large factor in the viability of applying machine data as a monitoring tool.
When machine data is applied to increase the accuracy of carbon sequestration forecasting models, machine data can provide an important step in the right direction, but will need to be combined with manual input for the best results. The list of field activities based on machine data can provide a good template for collecting input from the farmer, improving the accuracy of forecasts while limiting the increase in administrative burden.
More information
To wrap up our pilot we made the following analyses:
- A fit for purpose analysis of machine data with regards to carbon farming
- A fit for purpose analysis of the Ploutos Interopability Enabler (PIE) for exchange of machine data
- A description of the technical set up (architecture), with some first results in Github
If you have any interest in more detailed info from the above ↑, please leave your contact in the below ↓





Hi Anne,
Thank you for sharing the outcomes of the Carbon Farmin Pilot. At Spatialise we identify some opportunities based on the applicability of points 1 & 2.
Manually would not be feasible, but perhaps it is possible to do this automatically with the help of our API (for data export/import) which could be connected to the machine data. Spatialise already collects critical missing data such as carbon quantities, kg’s/hectares for Dutch farms on a regular basis and with in-field precision of 10×10 m.
Also, this way less sampling would be required as well.
Warm regards,
Souf/Spatialise
thank you for sharing. Very interesting insights. At BioScope we provide satellietdata-based insights in field activity, and indeed this is a valuable source of what has been done ánd what hasn’t. Moreover, our sat based soil analysis can serve as independent and objective proof, and in some regions we can even retrieve data from >10 years back, to establish baselines. Looking forward to see how both data sources compliment each other and get integrated in a reliable monitoring system for all regenerative agriculture practices, including carbon farming.