Door Anne Bruinsma
Data Delen en Carbon Farming
Voor een betrouwbare en kosteneffectieve compensatieregeling voor koolstofvastlegging is veel data nodig. Een veel gehoord uitgangspunt is dat data van de boer is, en zoveel mogelijk ook bij de boer moet blijven. Maar wat betekent dat precies in het geval van Carbon Farming? In deze blogpost beschrijven we onze eerste ervaringen met een technologische oplossing die data vrijer laat bewegen zonder dat de boer controle of keuzevrijheid verliest.
Achtergrond
In samenwerking met ZLTO en Udea werken we aan een compensatiesysteem voor koolstofvastlegging. Het gaat om een pilot binnen Ploutos, een Europees gefinancierd programma gericht op “data-driven sustainable agri-food value chains”. We bouwen daarbij door op een tool die NMI heeft ontwikkeld om boeren inzicht te geven in de potentie van de bodem. De tool is gebouwd als module binnen het BedrijfsBodemWaterPlan.
Koolstofvastlegging is een heel traag proces, dat lastig inzichtelijk te maken is. We leunen nu nog vooral op modellen om inzicht te verkrijgen in de koolstofbalans, in effecten van maatregelen en het voorspellen van waarden. We voeden die modellen met gegevens over onder meer bodemeigenschappen, het bouwplan, bemesting, het landbeheer en het klimaat.
Het doel is aan de ene kant om op bedrijfsniveau alles bij elkaar te brengen voor de boer: beleidsopgaven, onderliggende data, hoe je er als boer voor staat en wat je moet doen. Aan de andere kant is het van belang om betrouwbaar advies te kunnen geven over de effecten van maatregelen. Daarom zijn goede voorspellingen en monitoring ook van belang. Door scenario’s door te rekenen, verkrijg je inzicht in het toekomstig effect van je handelen.
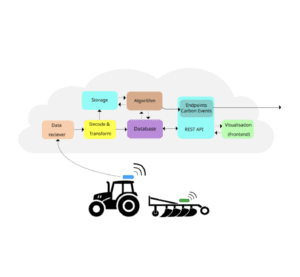
Een bijzonder onderdeel van het project is gericht op de meerwaarde van trekkerdata voor het modelleren van het koolstofgehalte in de bodem. Aan de hand van trekkerdata kunnen we maatregelen identificeren om deze gehaltes te berekenen. We kijken ook naar de impact van betere kwaliteit en completere (machine)data op de beoordeling van de CO2-voetafdruk.
Data delen: Ploutos common semantic model
Het inzamelen van data en monitoring kost geld. Dat is ook een reden waarom er nu voornamelijk met modellen wordt gewerkt. Maar ook de databehoefte van modellen is groot. Dus de vraag is hoe je het meest efficiënt en toekomstbestendig met data omgaat. Om kosten aan de voorkant te drukken, moet data makkelijk tussen systemen kunnen worden uitgewisseld.
In dit project testen we een door TNO ontwikkeld raamwerk dat gebruikmaakt van een gedeeld, open data model, waarmee op een gestandaardiseerde manier beschreven wordt welke partij welke data kan opvragen of leveren. Dit model biedt partijen de mogelijkheid om hun gegevens naar wie dan ook te exporteren, zonder eisen te stellen aan de onderliggende systemen van deze partijen zelf.
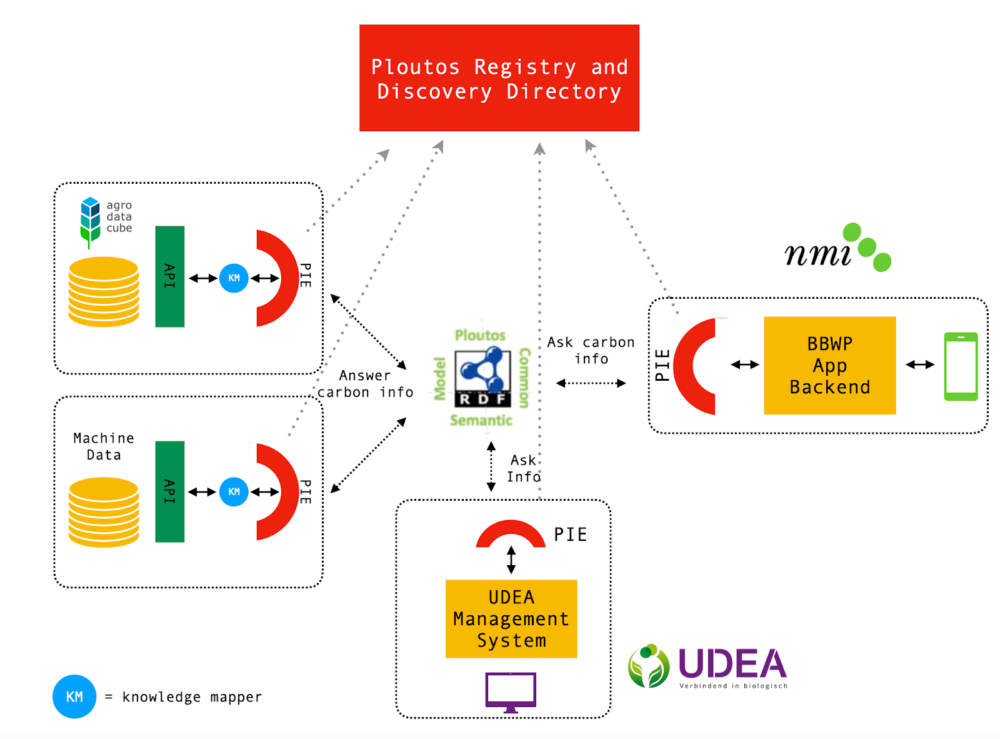
Technisch bevat het raamwerk het Ploutos Common Semantic Model en ondersteunende elementen (Registry en Discovery Directory en de combinatie van kennisvertalers en Ploutos Interoperability Enablers). Meer beschrijvend biedt het raamwerk (gitlab documentatie):
- een publiek register waarin alle databronnen vermeld zijn;
- per databron is beschreven welke informatie op te vragen is en/of benodigd is, en op welke manier;
- daarnaast bevat het model afspraken om te zorgen dat de uitgewisselde data goed met elkaar correspondeert, bijvoorbeeld over eenheden, benamingen of formaten
- middels een flexibele brugcomponent (de PIE) wordt zo de vertaalslag gemaakt van een afgesloten databron naar een publieke, beschreven en gestandaardiseerde bron.
Binnen onze pilot hebben we een minimaal scenario genomen waarbij TrekkerData, NMI en UDEA informatie met elkaar kunnen uitwisselen. We gaan dit nu uitwerken en een eerste maken, om te beoordelen of dit goed werkbaar is en in de toekomst opgeschaald kan worden.
Schematische weergave van de infrastructuur voor het delen van koolstofdata
Discussie
Deze manier van werken houdt in eerste instantie meer werk in dan het opslaan van gegevens in een database of data-uitwisseling tussen twee partijen. Maar we spelen wel in op de wens om dataverzameling en rapportage in de hele waardeketen goed te regelen. Er zijn hier ook alternatieve oplossingen voor in de maak, en pas in verder gebruik zal blijken wat de voor en de nadelen van onze Ploutos aanpak zijn, maar in ieder geval investeren we in het leren over slimme data connecties waar straks iedereen profijt van kan hebben.
De kracht specifiek van Ploutos Common Semantic Model en het Ploutos interoperability raamwerk is daarbij dat het partijen in staat stelt hun eigen onderliggende software en databases te blijven gebruiken. Hiermee kunnen partijen hun gegevens lokaal blijven opslaan en beheren, op de manier die zij zelf willen én tegelijkertijd toch interoperabiliteit bieden met andere complexe netwerken en systemen. De invloed van de manier van structureren van data via de PIE op een eigen implementatie is daarmee beperkt, en is het dus relatief net zo makkelijk om via de PIE uit te wisselen als via een directe API.
We zijn binnen het project nog bezig met het koppelen van de knowledge mapper en uitwisselen van endpoints. We moeten onderling nog bepaalde details afstemmen voordat we de koppelingen definitief maken. Maar omdat bijvoorbeeld het rekenhart van NMI open source is en er een API beschikbaar is, net als bij de Agro Data Cube, kunnen we ons inderdaad vooral richten op de verbindingen.
Trekkerdata is nog een relatief nieuwe databron. We zijn nog aan het finetunen welke soorten events we precies willen gebruiken als input voor het model. Door bijvoorbeeld het soort en intensiteit van grondbewerking te onderscheiden, kan het bodemmodel een nauwkeurigere berekening maken voor afbraak van bodemkoolstof. Ook bij deze databron is het mogelijk om via een API data op te vragen over activiteiten binnen een perceel binnen een bepaalde tijdsperiode.
Het project loopt tot september. Aan het einde van de zomer berichten we over de resultaten. Wil je op de hoogte blijven, laat dan even je email achter of neem even contact met ons op!





Hoi,
Ik zou graag meer willen weten over dit project, en vooral hoe we de resultaten en kennis kunnen gebruiken om hiervan te leren, maar ook om het te kunnen gebruiken voor veel meer thema’s
Groet Annelies
Hoi Annelies, ik breng je in contact met de projectleider! vg, Anne
Very interesting. Will it be translated in English or even Slovenian, since Slovenians are partners in Ploutus.
Let me check whether there is a placeholder for an English post, otherwise you will have to do with google translate 😉 If you have any questions, don’t hesitate to reach out 😉